考虑第4.8.1节中描述的另一种误差函数:
E(w)≡21d∈D∑k∈outputs∑(tkd−okd)2+γi,j∑wji2 为这个误差函数E推导出梯度下降更新法则。证明这个权值更新法则的实现可通过在进行表4-2的标准梯度下降权更新前把每个权值乘以一个常数。
先看一下表4-2的标准梯度下降权重更新法则:
表4-2 包含两层 sigmoid 单元的前馈网络的反向传播算法(随机梯度下降版本)
BACKPROPOGATION(training_examples,η,nin,nout,nhidden)traning_examples中每一个训练样例是形式为<x,t>的序偶,其中x是网络输入值向量,t是目标输出值。η是学习速率(例如0.05)。nin是网络输入的数量,nhidden是隐藏层单元数,nout是输出单元数。从单元i到单元j的输入表示为xji,单元i到单元j的权值表示为wji。⋅创建具有nin个输入,nhidden个隐藏单元,nout个输出单元的网络⋅初始化所有的网络权值为小的随机值(例如−0.05和0.05之间的数)⋅在遇到终止条件前:⋅对于训练样例traning_examples中的每个<x,t>:把输入沿网络前向传播1.把实例x输入网络,并计算网络中每个单元u的输出ou使误差沿网络反向传播2.对于网络的每个输出单元k,计算它的误差项δkδk←ok(1−ok)(tk−ok)3.对于网络的每个隐藏单元h,计算它的误差项δhδh←oh(1−oh)k∈outputs∑wkhδk4.更新每个网络权值wjiwji←wji+Δwji其中Δwji=ηδjxji
对于一个8x3x8的网络,详细图形如下:
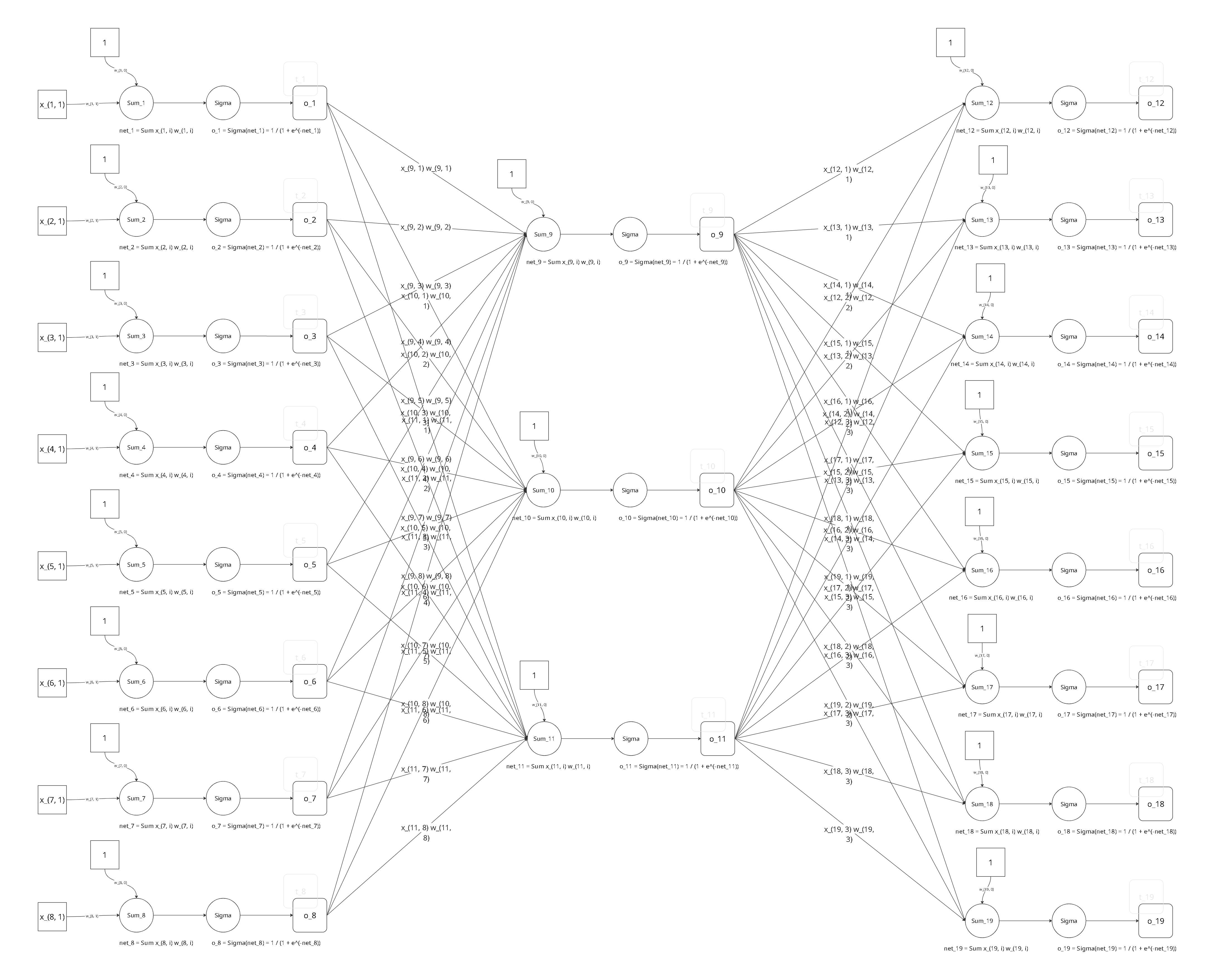
先来引入几个记号,以便于后面的推导。
令 Ed(w) 表示在训练样例 d 上的误差函数:Ed(w)≡21∑k∈outputs(tkd−okd)2。那么,在4.8.1节中描述的误差函数E可以写成:
E(w)≡d∈D∑Ed(w)+γi,j∑wji2 随机的梯度下降算法迭代处理训练样例,每次处理一个。对于每个训练样例d,本题要求利用整体误差 E 的梯度来修改权值。换句话说,对于每一个训练样例d,每个权 wji 被增加 Δwji:
Δwji=−η∂wji∂E 我们的目标是求出∂wji∂E的一个表达式,以便实现随机梯度下降法则。可以看出,
∂wji∂E=d∈D∑∂wji∂Ed+2γwji 我们剩下的任务就是为∂wji∂Ed推导出一个方便的表达式。首先,注意权值 wji 仅能通过 netj 影响网络的其他部分。
对于一个网络,其表示如下:
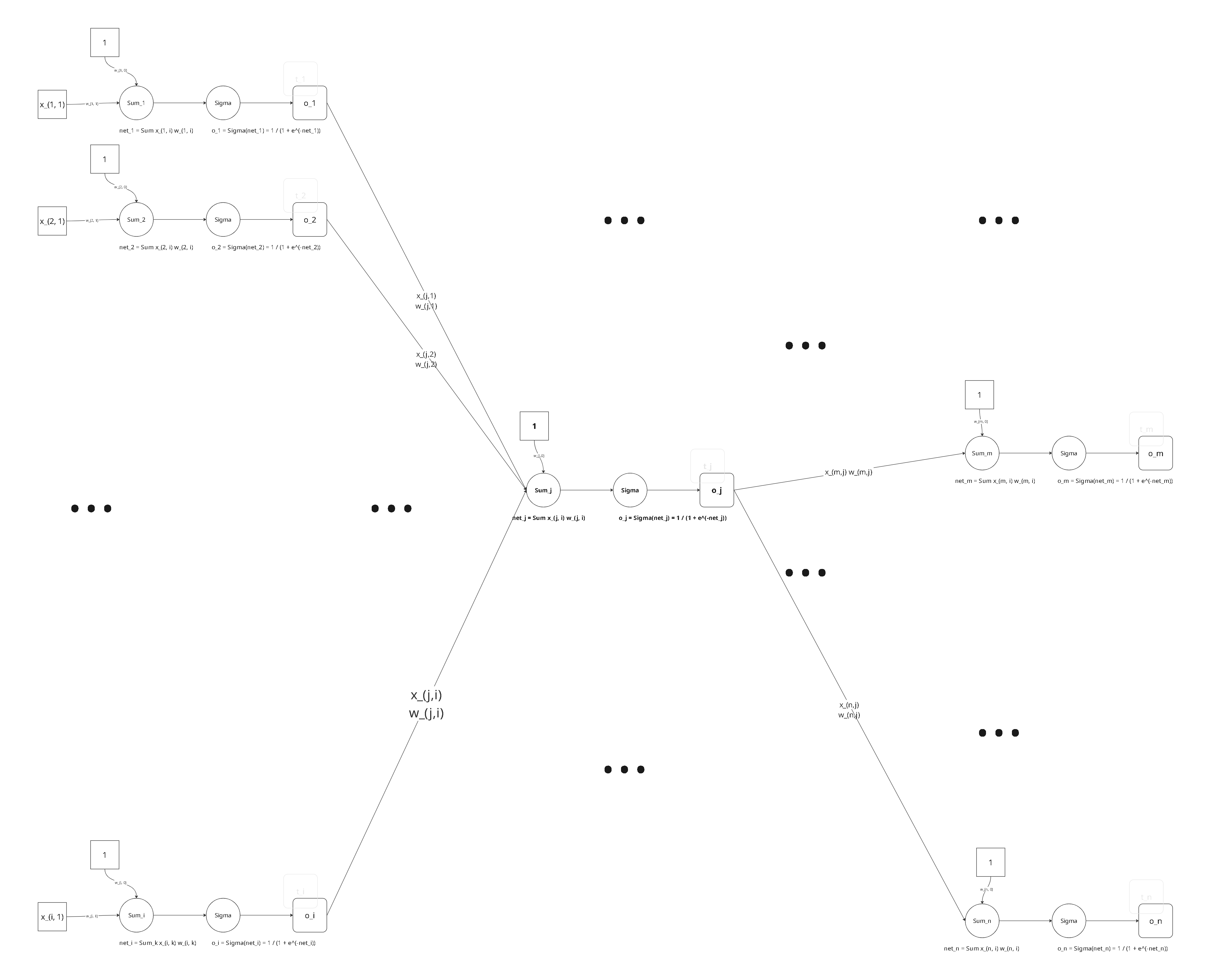
关注其中第 j 个单元,如下:
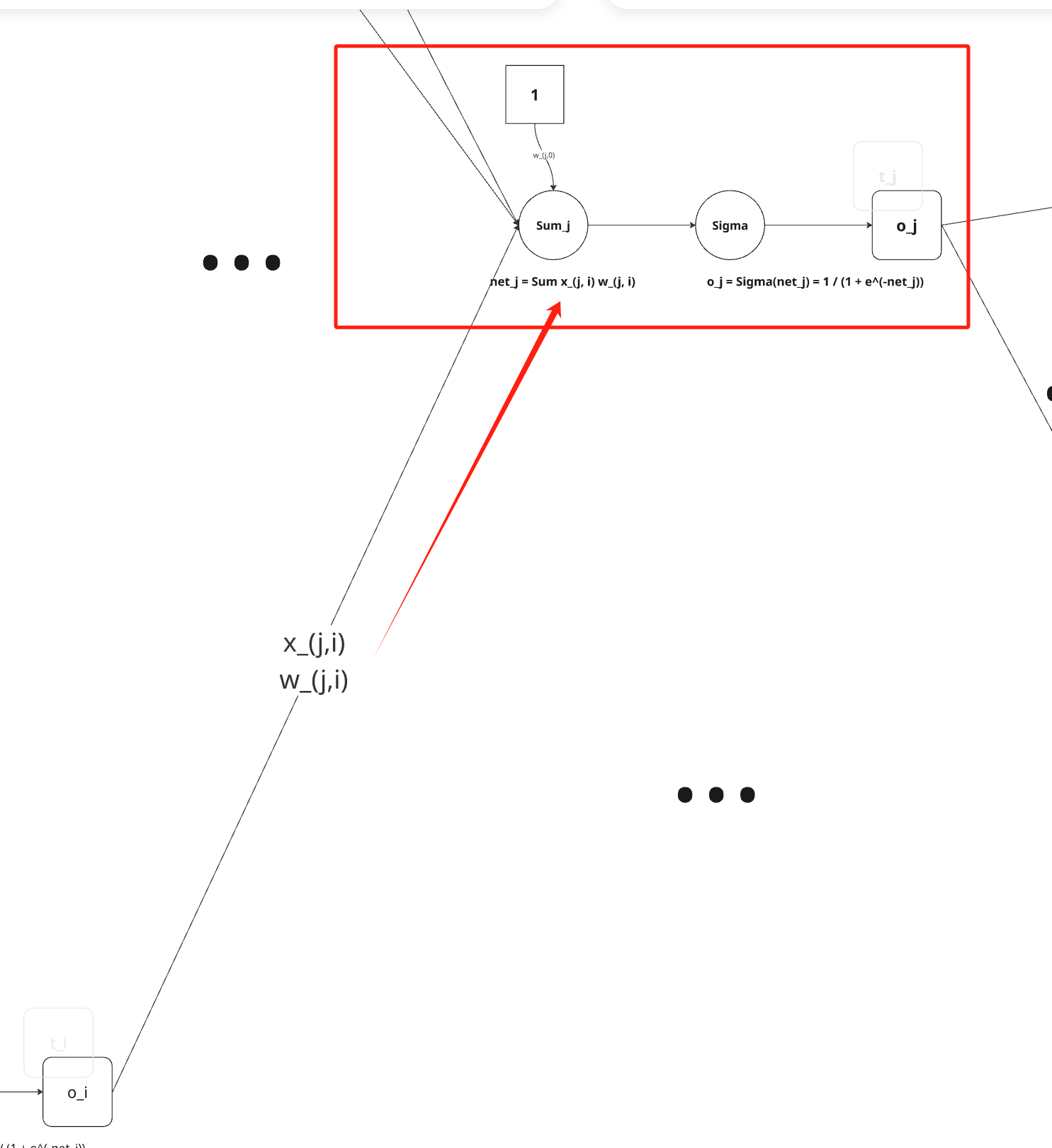
所以,我们可以使用链式法则得到:
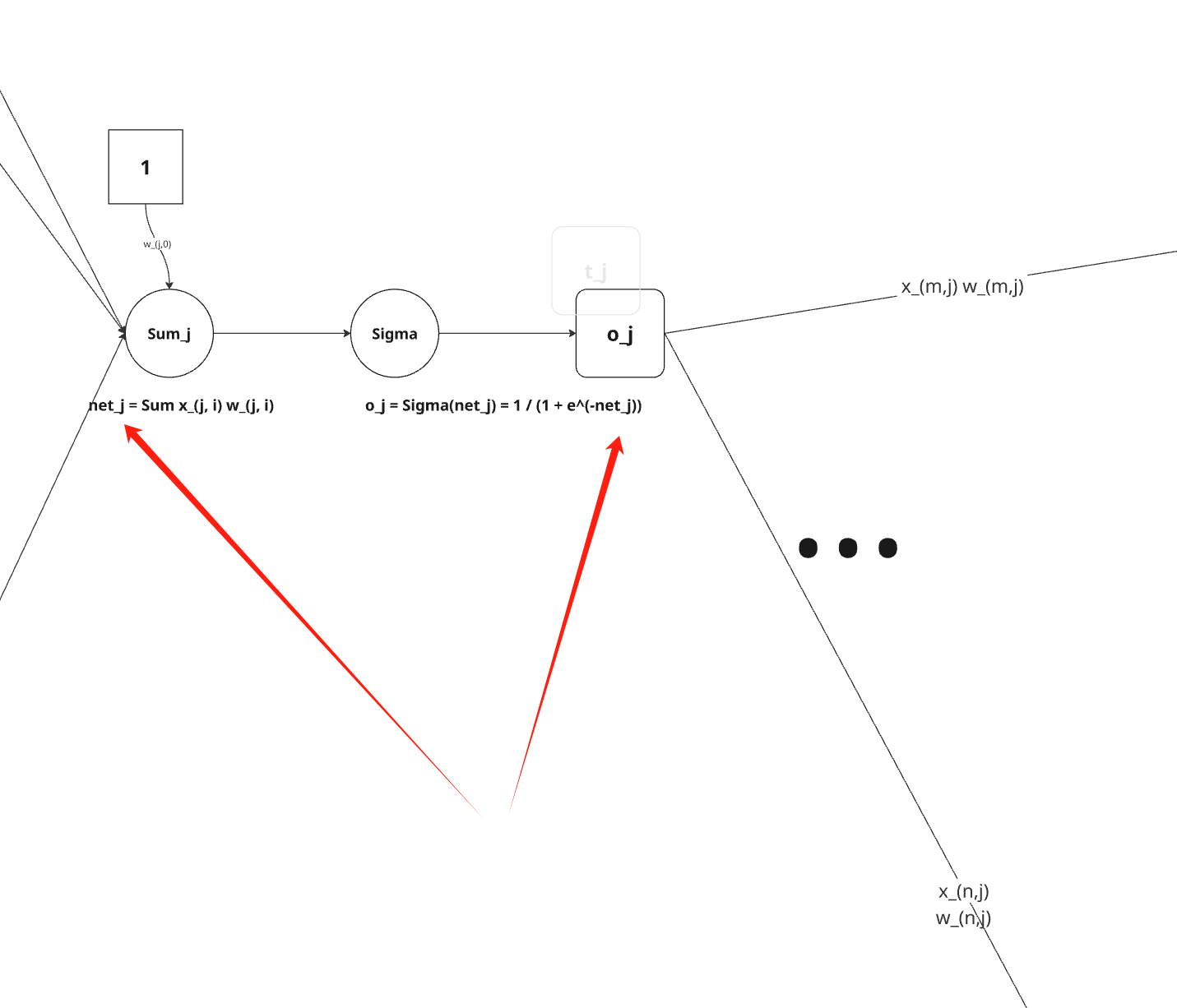
∂wji∂Ed=∂netj∂Ed∂wji∂netj=∂netj∂Edxji 于是剩下的任务就是为 ∂netj∂Ed 导出一个方便的表达式。我们依次考虑两种情况:一种情况是单元j是网络中的一个输出单元,另一种情况是单元j是网络中的一个内部单元。
情况1:输出单元的权值训练法则¶
就像 wji 仅能通过 netj 影响网络一样,netj仅能通过oj影响网络。
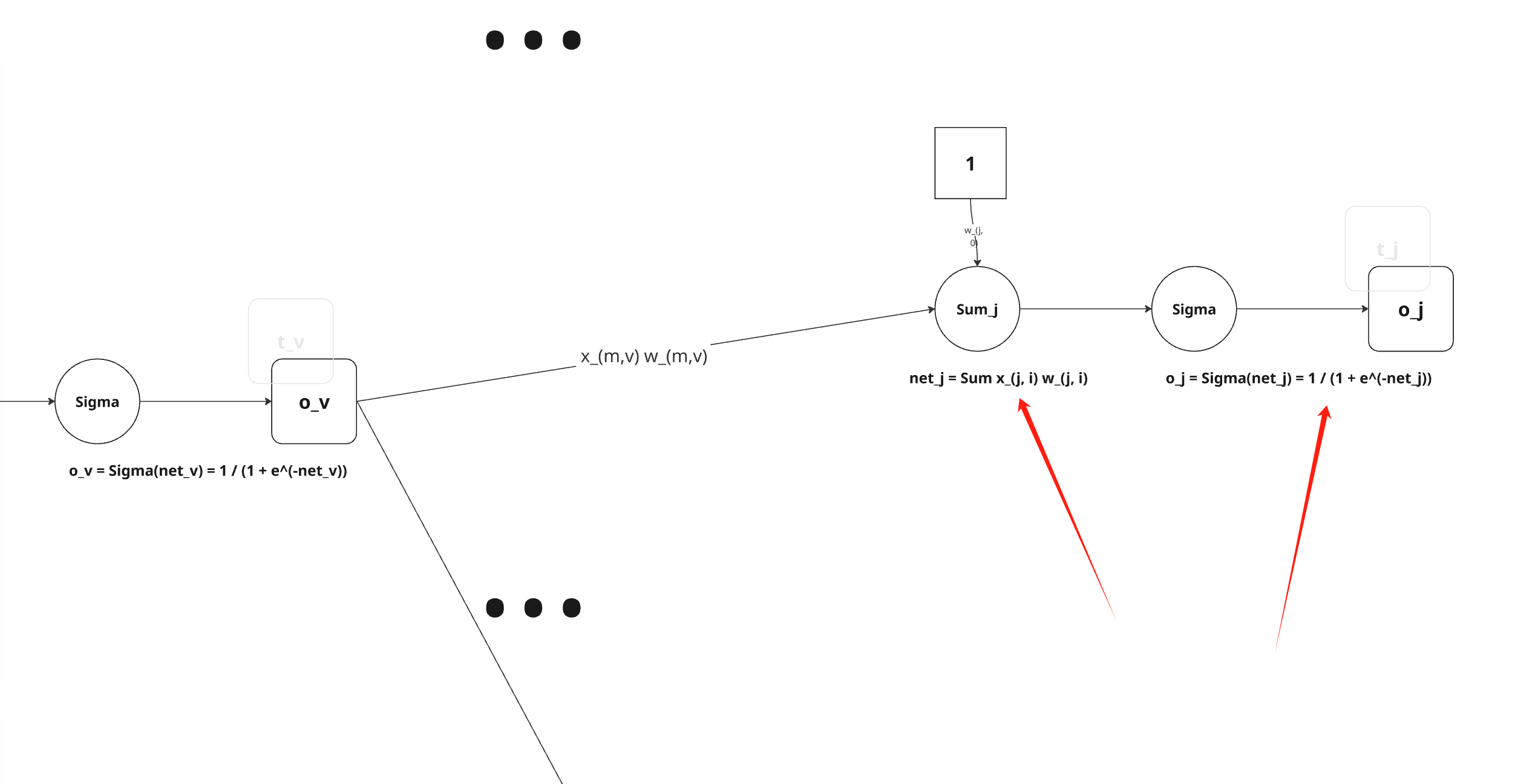
所以我们可以再次使用链式规则得出:
∂netj∂Ed=∂oj∂Ed∂netj∂oj 首先,仅考虑上式中的第一项:
∂oj∂Ed=∂oj∂(21k∈outputs∑(tk−ok)2) 除了当 k = j 时,所有输出单元 k 的导数 ∂oj∂(tk−ok)2 为0。所以我们不必对多个输出单元求和,只需设 k = j。
∂oj∂Ed=∂oj∂21(tj−oj)2=212(tj−oj)∂oj∂(tj−oj)=−(tj−oj) 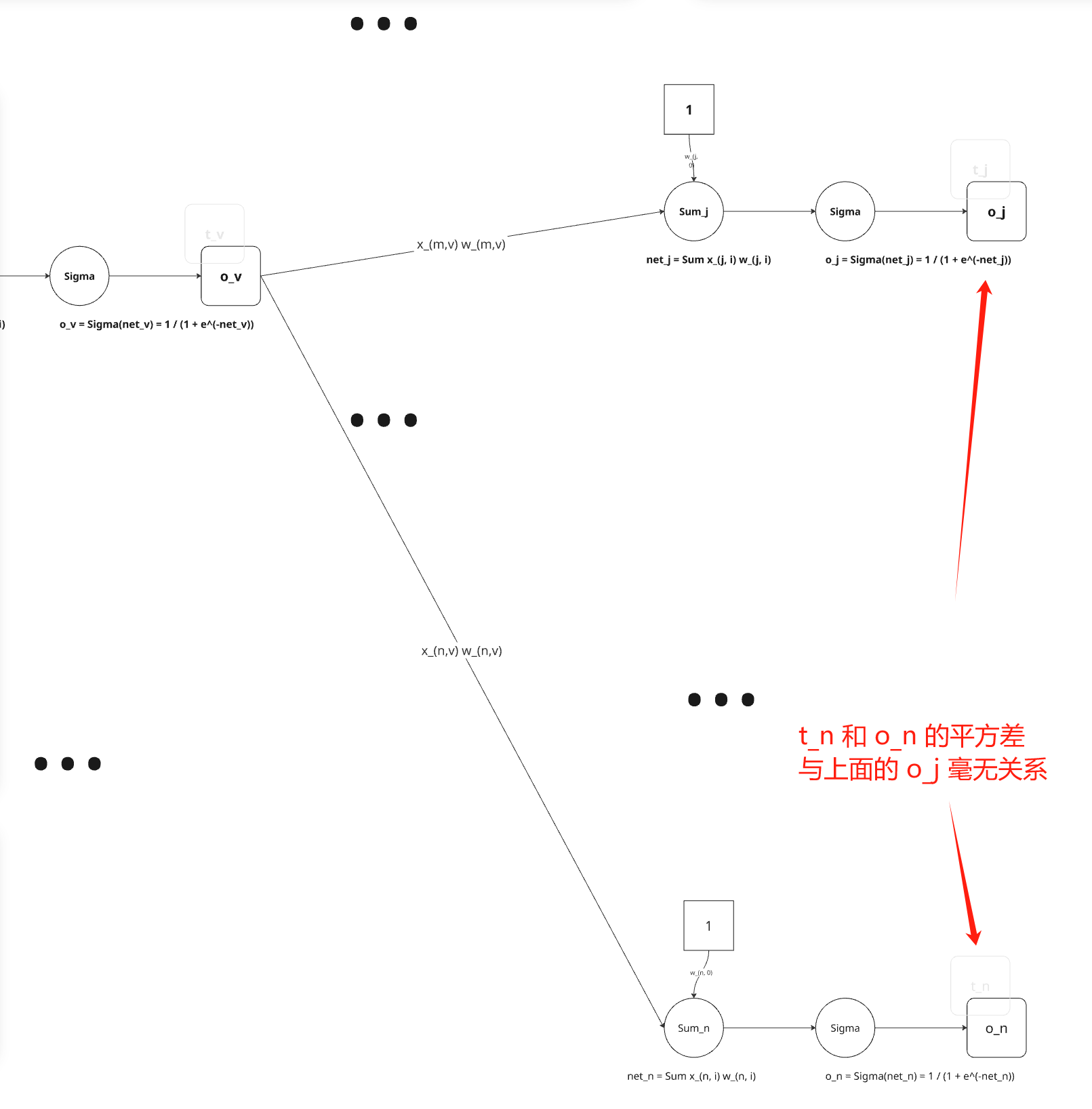
接下来考虑第二项。既然oj=σ(netj),导数∂netj∂oj 就是 sigmoid 函数的导数,即 σ(netj)(1−σ(netj))。所以:
∂netj∂oj=∂netj∂σ(netj)=oj(1−oj) 结合以上得到:
∂netj∂Ed=−(tj−oj)oj(1−oj) 结合以上,我们就得到了输出单元的随机梯度下降法则:
Δwji=−η∂wji∂E=−η(d∈D∑∂wji∂Ed+2γwji)=−η(d∈D∑(tj−oj)oj(1−oj)xji+2γwji)=−d∈D∑η(tj−oj)oj(1−oj)xji−2ηγwji 再回看表4-2中的权值更新法则:
wji←wji+Δwji其中Δwji=ηδjxji 而这里,输出单元的权值更新法则就对应的是:
wji←wji−d∈D∑η(tj−oj)oj(1−oj)xji−2ηγwji 如果令 δj=−∑d∈D(tj−oj)oj(1−oj),那么输出单元的权值更新法则就是:
wji←(1−2ηγ)wji+ηδjxji 所以,新的权值更新法则,就是在标准梯度下降权值更新以前,把每个权值乘以常数 (1−2ηγ)。
情况2:隐藏单元的权值训练法则¶
对于网络中的内部单元或者说隐藏单元的情况,推导 wji 必须考虑 wji 间接地影响网络输出,从而影响 Ed。由于这个原因,我们发现定义网络中单元 j 的所有直接下游单元的集合(也就是直接输入中包含单元j的输出的所有单元)是有用的。我们用 Downstream(j) 来表示这样的单元集合。
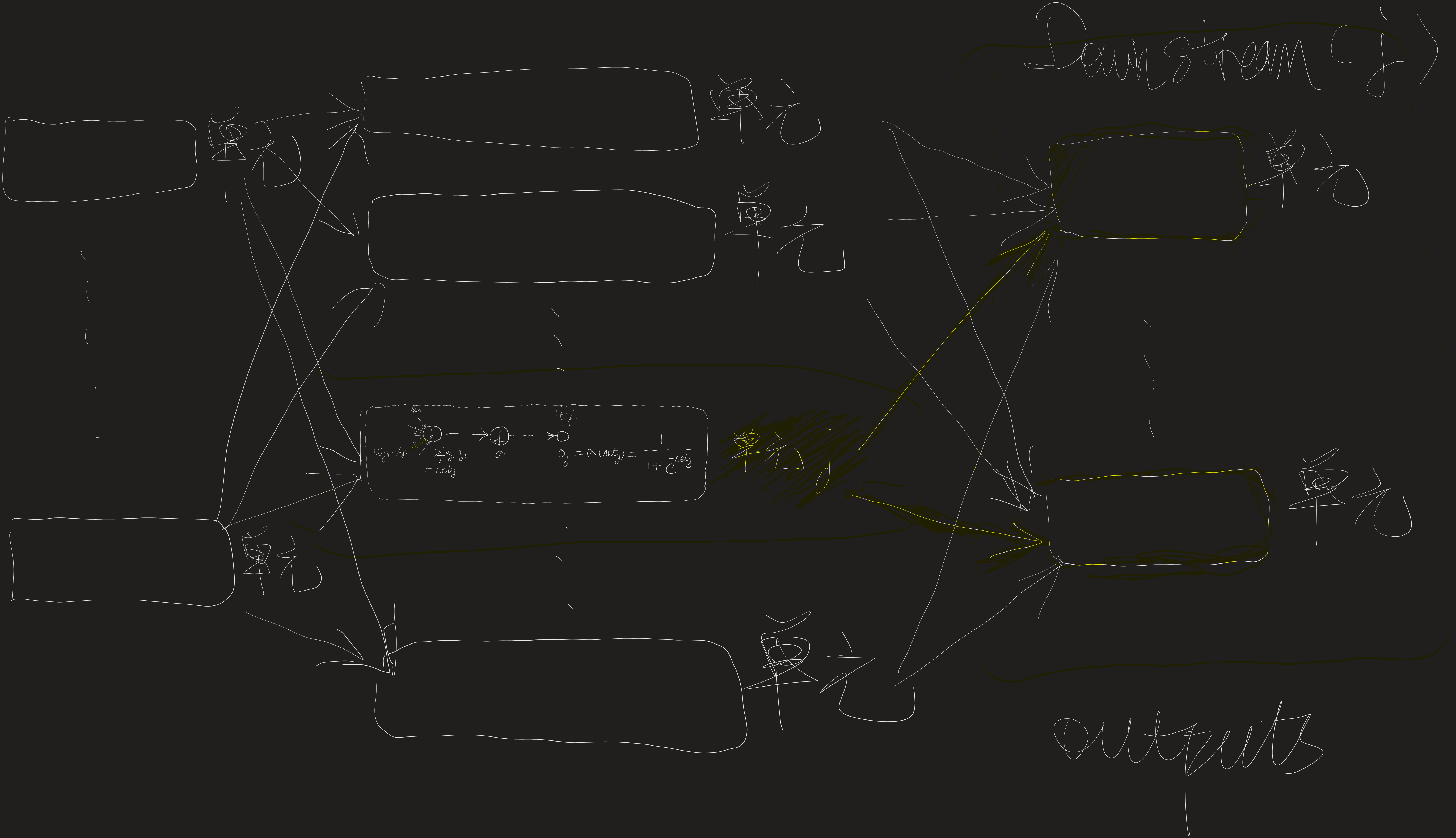
注意,netj只能通过Downstream(j)中的单元影响网络输出(再影响Ed)。
所以可以得出如下推导(注意,表4-2中的δk=−∂netk∂Ed):
∂netj∂Ed=k∈Downstream(j)∑∂netk∂Ed∂netj∂netk=k∈Downstream(j)∑−δk∂netj∂netk=k∈Downstream(j)∑−δk∂oj∂netk∂netj∂oj=k∈Downstream(j)∑−δkwjk∂netj∂oj=k∈Downstream(j)∑−δkwjkoj(1−oj)=oj(1−oj)k∈Downstream(j)∑−δkwjk 由于 δj=−∂netj∂Ed,我们可以把上式写成:
δj=oj(1−oj)k∈Downstream(j)∑δkwjk 于是,我们就得到了隐藏单元的随机梯度下降法则:
Δwji=−η∂wji∂E=−η(d∈D∑∂wji∂Ed+2γwji)=−η(d∈D∑∂netj∂Ed∂wji∂netj+2γwji)=−η(d∈D∑∂netj∂Edxji+2γwji)=−ηd∈D∑(−δj)xji−2ηγwji=−2ηγwji+ηd∈D∑δjxji 即隐藏单元的权值更新法则是:
wji←wji+Δwjiwji←wji−2ηγwji+ηd∈D∑δjxjiwji←(1−2ηγ)wji+ηd∈D∑δjxji 对比标准梯度下降权值更新法则,可以发现,对于隐藏单元来说,新的权值更新法则也是在标准梯度下降权值更新之前将每个权值乘以了常数 (1−2ηγ)。