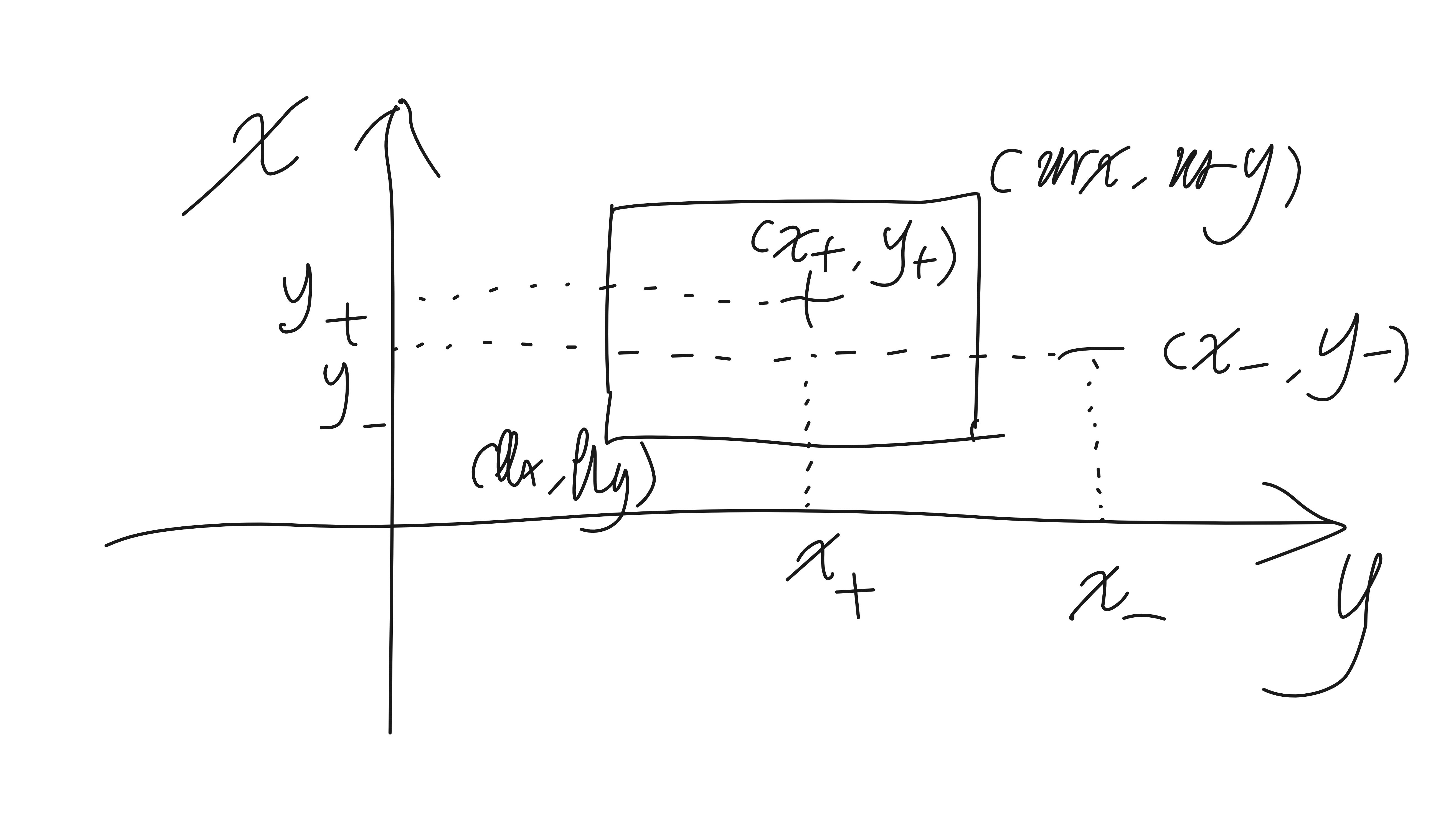
推导出学习 x, y 平面上的矩形这一目标概念的梯度下降算法。使用 x, y 的坐标描述每一个假设,矩形的左下角和右上角分别表示为 llx, lly, urx 和 ury。实例<x, y>被假设<llx, lly, urx, ury>标记为正例的充要条件是点<x, y>位于对应的矩形内部。按本章中的办法定义误差 E。试设计一个梯度下降算法来学习这样的矩形假设。注意误差 E 不是 llx、lly、urx 和 ury 的连续函数,这与感知器学习的情况一样(提示:考虑感知器中使用的两个解决办法:(1)改变分类法则来使输出预测成为输入的连续函数;(2)另外定义一个误差——比如到矩形中心的距离——就像训练感知器的 delta 法则)。当正例和反例可被矩形分割时,设计的算法会收敛到最小误差假设吗?何时不会?该算法有局部极小值的问题吗?该算法与学习特征约束合取的符号方法相比如何?
不连续的误差函数¶
要根据样本学习(猜测)到矩形的边界:llx, lly, urx 和 ury。而样本值是 (x, y) 坐标以及标签 t(1 表示在矩形内,0 表示在矩形外)。所以我设想的这个人工神经网络结构是 2 个输入,4 个输出,分别对应于 llx, lly, urx 和 ury。
判断矩形的边界是否正确可以通过计算每个样本的预测值与真实值之间的误差来实现。我们可以定义一个误差函数 E,来衡量预测的矩形与真实矩形之间的差距。
其中 和 分别是训练集中的目标值和利用神经网络的输出值计算出来的一个值,详细来说,
可见,由于存在阶跃性的激活函数,误差函数 不是 的连续函数,也不是 llx, lly, urx, ury 的连续函数。
样本数据示例¶
以下给出三组小型数据集用于调试与可视化。格式为 CSV:x,y,t,其中 t=1 表示在目标矩形内,t=0 表示在外。
1) 可分数据(目标矩形:llx=1, lly=1, urx=4, ury=3)
x,y,t
1.5,1.2,1
2.0,2.5,1
3.5,1.1,1
1.1,2.9,1
2.7,1.8,1
3.9,2.2,1
0.5,1.5,0
4.5,2.0,0
2.5,0.6,0
2.5,3.6,0
-1.0,2.0,0
2.0,4.0,02) 含噪声/近边界数据(目标矩形:llx=0, lly=0, urx=1, ury=1;含少量错标)
x,y,t
0.10,0.20,1
0.80,0.90,1
0.50,0.50,1
0.02,0.98,1
1.20,0.50,0
-0.20,0.70,0
0.40,1.10,0
1.05,0.95,1
0.95,0.05,0
0.99,0.99,13) 类别不平衡数据(目标矩形:llx=-2, lly=-1, urx=0.5, ury=0.8;正例稀少)
x,y,t
-1.0,0.0,1
0.10,-0.50,1
1.00,0.00,0
0.60,0.90,0
-2.50,0.00,0
0.00,1.20,0
1.50,1.50,0
-3.00,-2.00,0
0.80,-1.50,0
2.00,0.50,0解决办法¶
改变分类法则来使输出预测成为输入的连续函数¶
前面设想的神经网络结构,和误差定义,由于存在阶跃性的激活函数,导致误差函数 不是 的连续函数,也不是 llx, lly, urx, ury 的连续函数。
现在改变思路,用平滑的激活函数替代阶跃函数,使得输出预测成为输入的连续函数。比如,使用
其中
另外定义一个误差——比如到矩形中心的距离¶
比如,对于一个出现的样本,不再用它是否在矩形内来做一个二分判断,而是用一个平滑的函数来表示它在矩形内的“程度”。比如不再输出它是否在矩形内的二值,而是输出一个它离矩形中心的距离。这个距离可以通过以下公式计算:
为了验证这个是否可行,可以在下面用一个交互式 iframe 来展示。以下是一个可以交互的网页,用户可以通过拖动矩形的四个角来调整矩形的位置和大小,并且可以添加样本点来观察误差的变化。
可以看出,当给定个 (x, y) 的样本点时,误差函数是连续的,并且可以通过梯度下降法来优化 llx, lly, urx 和 ury 的值,从而最小化误差。
这时的误差定义为:
其中 是样本点 (x, y) 到矩形中心的真实距离。